
Grafikaĵoj
Danke al la AJSP datenaro de la Max Planck instituto, mi povis sekvi la metodon de Müller kaj grupo por fari ĉi tiujn grafikaĵojn per MDS.
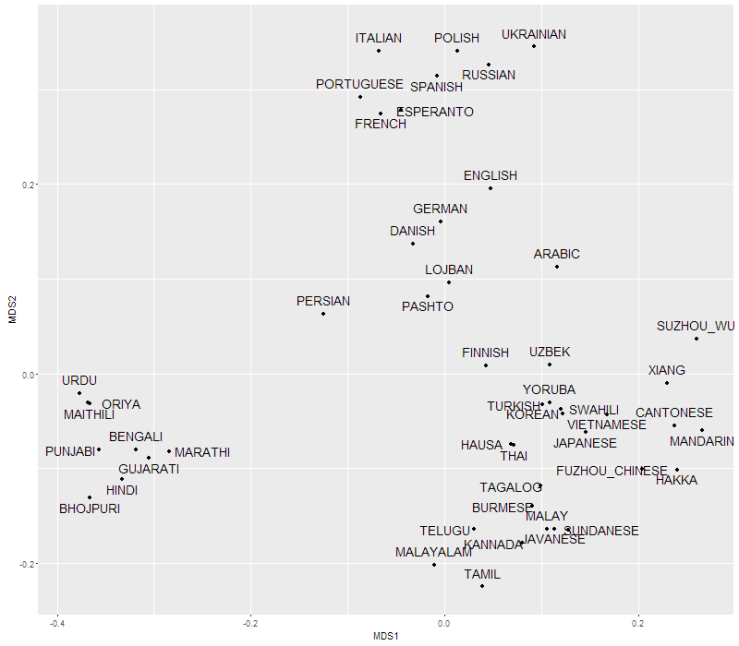
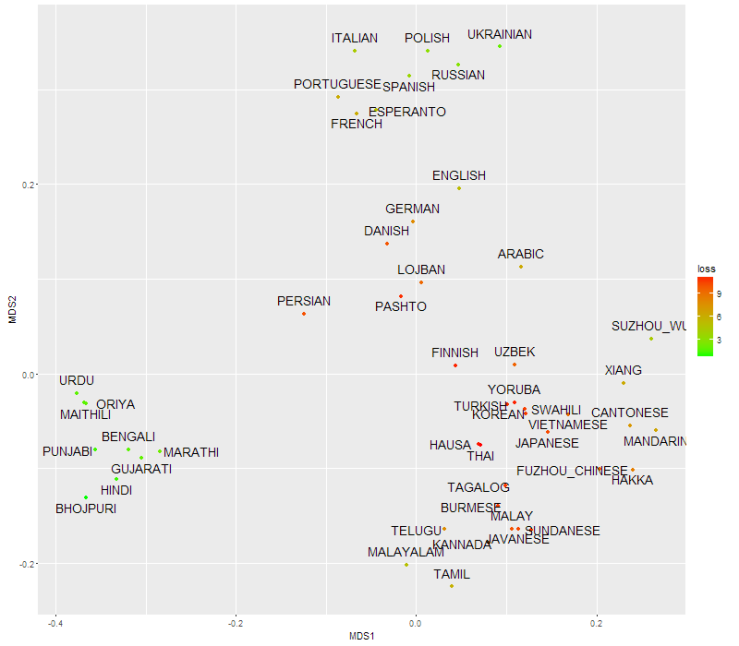

Diskuto
Estas ĝenerale grandaj diferencoj inter la lingvoj laŭ la elektita distanca mezuro. Kvankam la distanca matrico havas kelkaj videblaj lingvaj grupoj, la lingvoj estas tre dise. Aldone, en la MDS-grafikaĵo estas multaj punktoj, kiuj ne taŭgas por siaj taksitaj pozicioj. Simple ne estas sufiĉe da spaco por distribui la punktojn sur dudimensian ebenon sen meti iujn punktojn tro proksime aŭ malproksime. Lingvoj apartenas pli bone en multdimensia spaco.
Esperanto kaj Lojban
Estas facile lerni lingvojn proksime al onia denaska lingvo(Isphording, I.E. and Otten, S., 2011), tial mi relative facile lernis la anglan lingvon. Esperanto fariĝis por ke pli da homoj havus facilan, komunan lingvon. Tamen, homoj ofte akuzas Esperanton, ke ĝi estas eŭropa lingvo. Ili diras, ke kandidatiĝanta globala lingvo ne devus aparteni al nur unu lingva grupo. Evidente, Esperanto estas eŭropa lingvo, sed ekzistas alternativo? Ĉar lingvoj kuŝas en multdimensia spaco, miksaĵo de ĉiuj lingvoj estus malproksime de ĉiuj lingvoj. Ekzemplo estas Lojban, kiu estis kalkulita en 1987 bazite sur la mandarina, angla, hispana, hindia, rusa kaj araba lingvo. Lojban estas lokita en la centro de la MDS-grafikaĵo kaj fakte apartenas al la eŭropa lingva grupo laŭ la evoluarbo. Tamen, la distancoj inter lojban kaj ĉiuj aliaj lingvoj estas grandaj kaj la lingvo nur kuŝas en la centro, ĉar alternativa loko mankas. Per la elektita distanca mezuro, Esperanto estas tiom malfacila por ne-eŭropanoj, kiom Lojban estas por ĉiuj.
Metodo
La Swadesh-a listo estas listo de la 100 homaraj konceptoj kiel mi, kiu, monto, audi, granda kaj tiel plu. La listo uzus por kompari diversajn lingvojn per iliaj tradukoj de la konceptoj. Post la kreado de la listo, ĝi pliiĝis al 207 vortoj por pliigi la statistikan, determinan povon(statistical power). Post tio ĝi malpliiĝis al tiuj 40 vortoj, kiuj portas la plejparton de la statistika determina povo. (Ŝajnas ke oni anstataŭ devus uzi pli bonan statistikan modelon, sed tiel mi ofte pensas pri multaj aferoj).
La Max Planck instituto faris la datenaron AJSP enhavante la Swadesh-an liston en pli ol 7000 lingvoj. Ĉiuj tradukoj estas skribita en la sama fonetika skribsistemo. Tio permesas sisteme trakti la datenaro, kiel Müller kaj kunlaborantoj faris tielmaniere:
- La distanco inter du vortoj estas la normigita Levenshtein-distanco(LDND).
- La Levenshtein-distanco(LD) estas la plej malgranda nombro de operacioj, kiu necesas por transformi la unan vorton al la alian.
- Operacio estas aŭ substitui, aŭ forigi aŭ aldoni literon.
- La normigito konsistas el 2 paŝoj.
- Dividi la distancon LD per la longeco de la plej longa vorto. La rezulto estas LDN.
- Dividi LDN per la averaĝa LDN de aliaj vortoj el la du lingvoj.
- La Levenshtein-distanco(LD) estas la plej malgranda nombro de operacioj, kiu necesas por transformi la unan vorton al la alian.
- La para distanco inter du lingvoj estas la averaĝa distanco inter la vortoj de la du lingvoj.
- Paraj distancoj inter ĉiuj lingvoj faras evoluarbon por ĉiuj lingvoj per Neighbour joining.
- Evoluarbo klarigas evoluan historion inter elementoj kvazaŭ ĉi tie por Homo, simio kaj muso.
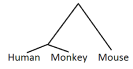
- Evoluarbo klarigas evoluan historion inter elementoj kvazaŭ ĉi tie por Homo, simio kaj muso.
Plejparte mi rekreis la procedon de la grupo de Müller, sed mi faris aliajn elektojn por atinigi ‘mapon’ de la lingvoj de la mondo:
- La distanco inter du vortoj estas la normigita Levenshtein-distanco(
LDNDLDN).- La Levenshtein-distanco(LD) estas la plej malgranda nombro de operacioj, kiu necesas por transformi la unan vorton al la alian.
- Operacio estas aŭ substitui, aŭ forigi aŭ aldoni literon.
- La normigito konsistas el
21 paŝoj.- Dividi la distancon LD per la longeco de la plej longa vorto. La rezulto estas LDN.
Dividi LDN per la averaĝa LDN de aliaj vortoj el la du lingvoj.
- La Levenshtein-distanco(LD) estas la plej malgranda nombro de operacioj, kiu necesas por transformi la unan vorton al la alian.
- La para distanco inter du lingvoj estas la averaĝa distanco inter la vortoj de la du lingvoj.
- Paraj distancoj inter
ĉiujkelkaj lingvoj faras evoluarbon porĉiujkelkaj lingvoj per Neighbour joining.- Evoluarbo klarigas evoluan historion inter elementoj kvazaŭ ĉi tie por Homo, simio kaj muso.
- Evoluarbo klarigas evoluan historion inter elementoj kvazaŭ ĉi tie por Homo, simio kaj muso.
- Paraj distancoj inter kelkaj lingvoj faris ‘mapon’ de kelkaj lingvoj pere Multidimensional scaling(MDS).
- Multidiemnsional scaling transformas para distancaro al punktoj en n-dimensia ebeno. Imagu, ke ni konis la parajn distancojn inter ĉiuj danaj urboj, sed ne iliajn poziciojn. Tiuokaze, MDS(kun n=2) konstruus bonan takson de la faktaj pozicioj de la danaj urboj per la paraj distancoj. Praktike, MDS minimumigas la diferencojn inter la faktaj distancoj kaj la distancoj de la taksata mapo.
- Mi designas la distancan matricon.
- En la distanca matrico ĉiu vico apartenas al lingvo kaj ĉiu kolumno apartenas al lingvo. Do, kvanto en matrico indikas la distancon inter la vica lingvo kaj la kolumna lingvo.
Mi ne uzis LDND, ĉar mi pensas ke ĝi estas stranga kaj ne vere necesa. Mi nur uzis subaron de la lingvoj, ĉar mi volis fari malgrandan mapon. Mi inkludis tiujn 45 lingvojn, kiuj havas la plej grandajn nombrojn de denaskulaj parolantoj, kaj miajn amitajn/malamitajn lingvojn la danan, esperanto, la lojbanan kaj finan lingvon. Mi ne tute inkludis tiujn kvar lingvojn en la MDS-kalkulado por ne influi la pozicioj de la aliaj lingvoj. Mi atingis tion per pezigi la kvar lingvojn tre malgrandaj.
La datumaĵoj estas elŝuteblaj sur la AJSP retpaĝo (por fari kiel mi ekzakte, oni bezonas la zip-dosierion Dataset in CLDF [10.9MB]). La fontkodo estas sur github en la nova, bonega dosierformo Rstudio Notebook.

Lingvoj estas pli ol listo de 40 leksemoj.
Antaŭ jaroj, kiam André Müller, kiun mi persone konas kaj ŝatas, prezentis la projekton kaj la rezultojn al la jarkonferenco de la Societo pri Interlingvistiko, mi jam miris, ke MPI entute entreprenis tian projekton.
Leksika statistiko estas tute misa aliro, per kiu oni povas montri ĉion kaj nenion. Ĝi nek taŭgas diakronie, por kalkuli tempajn distancojn aŭ parencecon de lingvoj, nek sinkronie, por montri lingvan proksimecon. Efektive ne tute, la kulmina rezulto de la metodo estas, ke ĝi povas preskaŭ fidinde re-modeligi la parencecajn rilatojn, kiujn lingvistoj jam longe ekkonis per aliaj rimedoj.
Do mi neniam bazus ajnan diskuton sur rezultoj atingitaj per leksika statistiko.
LikeLike
Kiajn statistikojn aŭ rimedojn vi preferus?
Kompreneble, io estas perdita per la swadesh-metodo, tial la rezultoj estas malpli precizaj ol la optimumaj. Sed la metodo estas facila kaj konvinkanta por ne-lingvistoj kaj ĝi faras instruan, tutan bildon. Do mi pensas, ke la metodo aldonas valoron al lingvismo.
LikeLike
Mi mi scias, ĉu ekzistas statistikaj metodoj por tiu celo, kiuj iel taŭgas – mi ĝis nun ne vidis.
Kompreneble, estas alloge desegni tiajn arbojn/bildojn, tamen ilia scienca valoro estas nula en komparo al la tradiciaj metodoj – kompari ne nur grandan kvanton da leksemoj, estigi nehazardajn fonologiajn rilatojn inter ili (t.n. sonleĝoj*) kaj antaŭ ĉio kompari la gramatikojn de la lingvoj kaj ties diakronian evoluon.
Neniu povus serioze aserti, ke por germano la paŝtua aŭ araba estas pli proksimaj, pli facile lerneblaj ol la itala, sed tiajn distancojn mi vidas en la bildo generita per statistiko.
*Ties manko estas ĉefa miso de la statistika aliro. Mi ne memoras, ĉu estis en la laboro de Müller aŭ iu alia, sed mi memoras, ke la programo mezuris la similecon ekz. de hispana ‘fuego’ kaj germana ‘Feuer’ “fajro”. Sed tiu du vortoj havas malsamajn etimojn, ilia simileco estas tute hazarda.
LikeLike
Hmm.. bonaj argumentoj. Mi komprenas ke la kalkulada lingvismo (ankoraŭ) ne estas tiom sperta kiom la alia lingvismo. La kalkulada lingvismo povas fari aliajn aferojn. Ekzemple, La evoluarbo estas interesa sed oni bezonas kvantojn por taksi ĝin en sistema maniero. Por tio, kalkulada lingvismo estas pli bona.
Eble, la plej granda problemo pri la taksitaj evoluarboj estas, ke ili enhavas evidentajn erarojn. Tiuj verŝajne aperas pro vario en la datenaro. Tial, la evidentaj eraroj eble malaperus en analizo kun konfidentaj intervaloj.
LikeLike
Chu el la evoluarbo sekvas, ke – lau la leksemsimileco – al la germana estas pli proksima la pashtua (kvar pasendaj disbranchighnodoj), ol la itala (dek pasendaj disbranchighnodoj)?
LikeLike
Jes, per malgranda kvanto;)
LikeLike
En la artikolo tekstas: “Per la elektita distanca mezuro, Esperanto estas tiom malfacila por ne-eŭropanoj, kiom Lojban estas por ĉiuj.”
Sed el la 45 lingvoj aperantaj en la evoluarbo estas nur la franca, portugala, hispana kaj itala, por kiuj la “vojo” al Lojban entenas unu disbranchighnodon pli, ol la “vojo” al Esperanto.
Okaze de la aliaj lingvoj estas ech tiel, ke la “vojo” al Lojban entenas unu disbranchighnodon malpli, ol la “vojo” al Esperanto.
Tio estas en la kontraudiro al la supra citajho. Kion mi pretervidas?
LikeLike
Ne estas kontraŭdiro, ĉar la distanco inter du lingvoj estas proksime la alteco, kie iliaj du linioj renkontiĝas. La nombro de nodoj inter du lingvoj ne gravas.
LikeLike
Tio signifas, ke al la germana estas pli proksima la mandarena, ol la hindia. Au chu mi pretervidas ion gravan?
LikeLike
Jes, vi pravas. Sed mi dubas la statistikan signifon de tio.
LikeLike
Jen subjektivaj komparoj de la germana kun la hindia kaj mandarena je la samaj cent vortoj de la Swadesh-listo:
https://goo.gl/4WtGMI
Al la germana shajnas pli simila la hindia, ol la mandarena. Kial tio ne retrovighas en la evoluarbo?
LikeLike
Jes la LDN distanco inter la hindia kaj la germana estas 0.8324324 kaj la distanco inter la germana kaj la mandarena estas 0.9454545. La evoluarba metodo estas nur proksimumo, sed la proksimumo estas ja iomete stranga. Mi provos trovi klarigon en la metodo.
LikeLike